Publications
2026
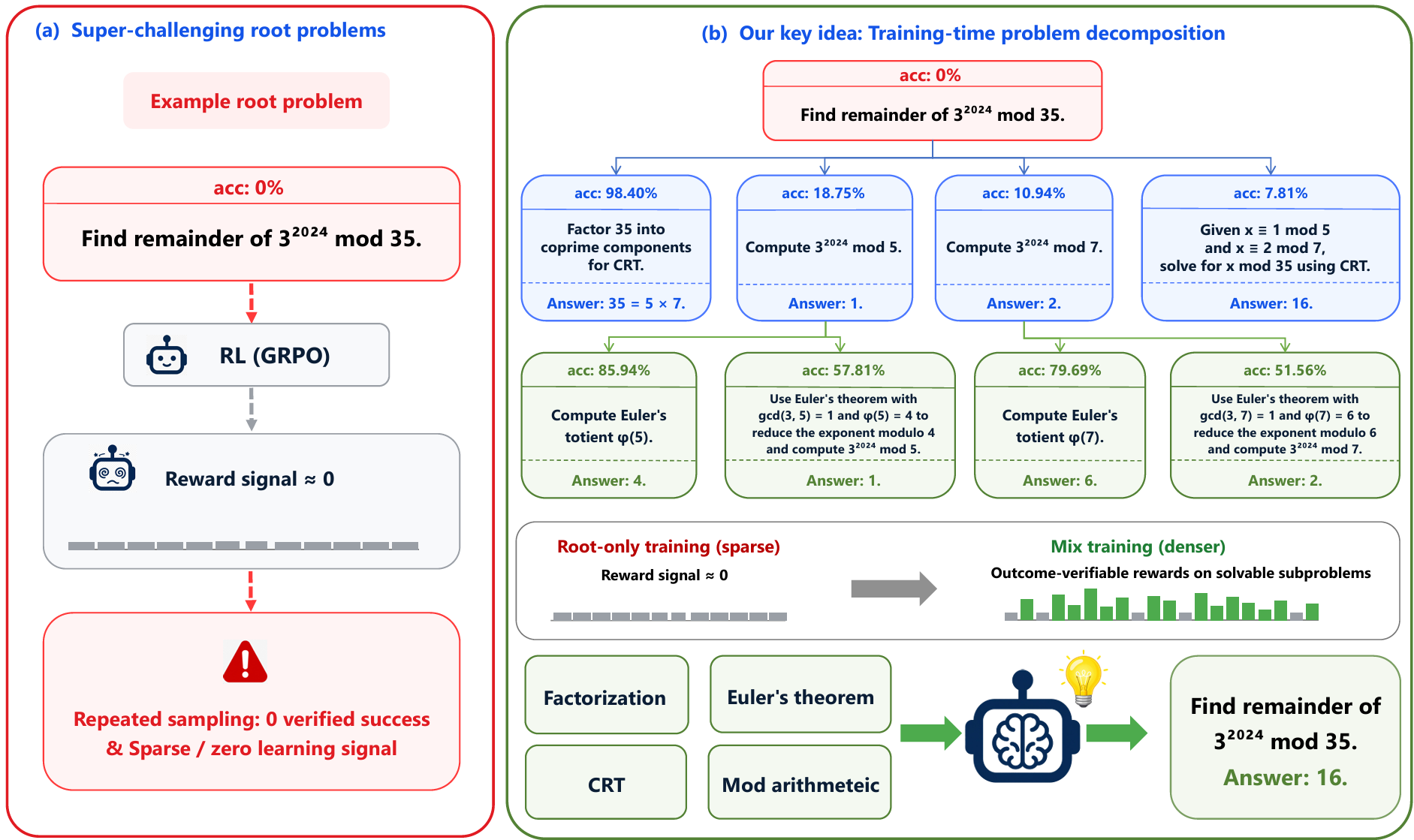
TD-Grokking: Learning from Zero-Reward Problems by Training-Time Decomposition
03 Jun 2026
·
arXiv:2606.09883
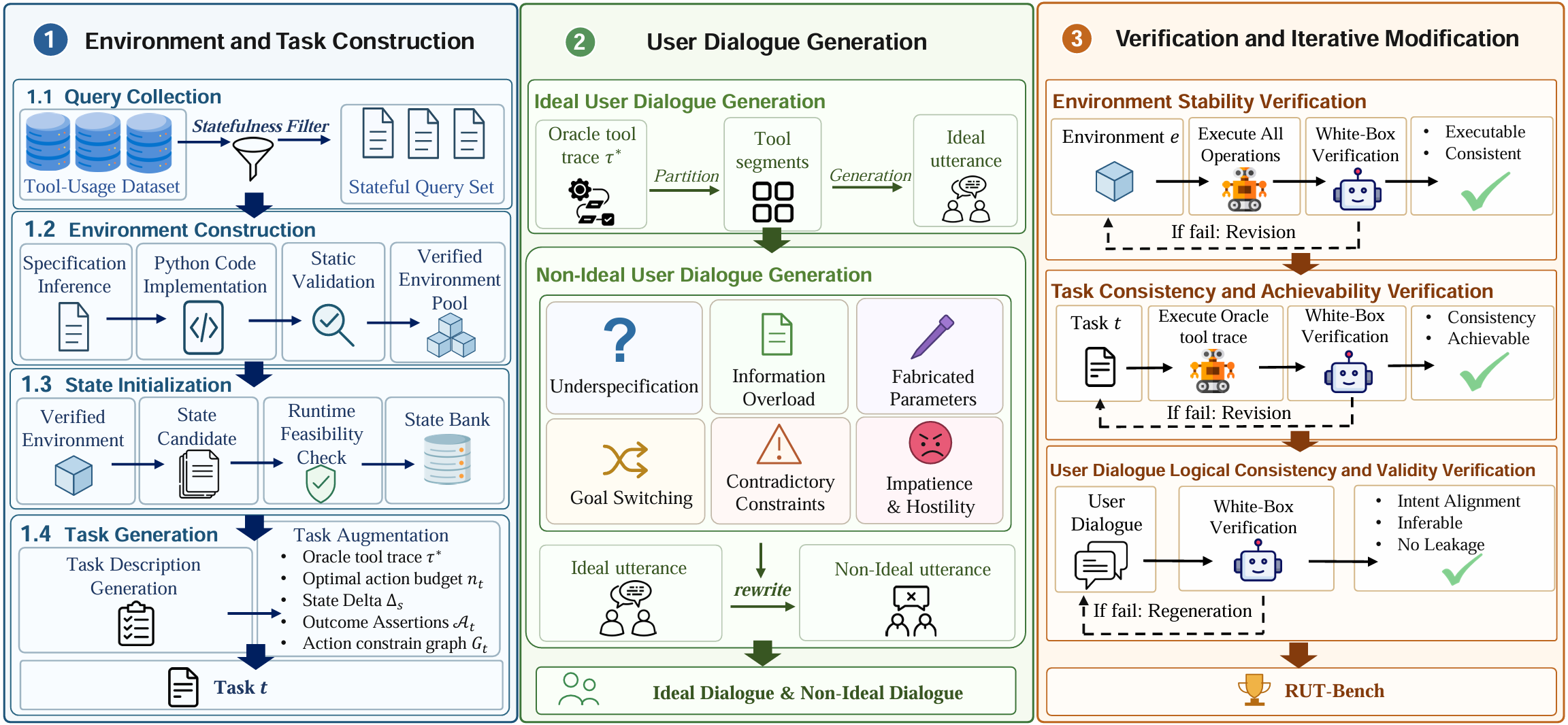
Beyond Ideal Instruction: A Comprehensive Framework for Evaluating LLMs in Realistic Interactions
02 Jun 2026
·
arXiv:2606.03318
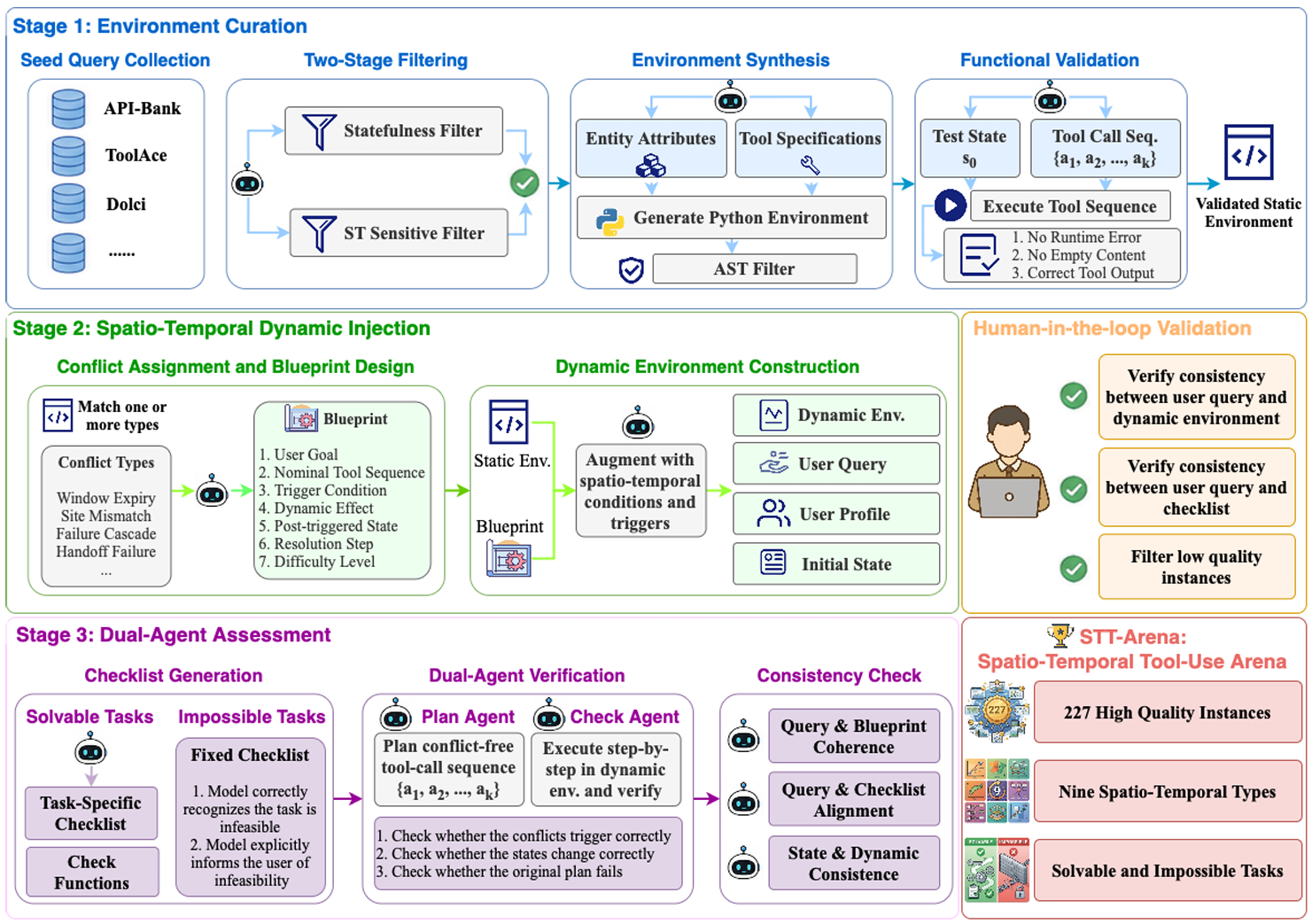
STT-Arena: A More Realistic Environment for Tool-Using with Spatio-Temporal Dynamics
18 May 2026
·
arXiv:2605.18548
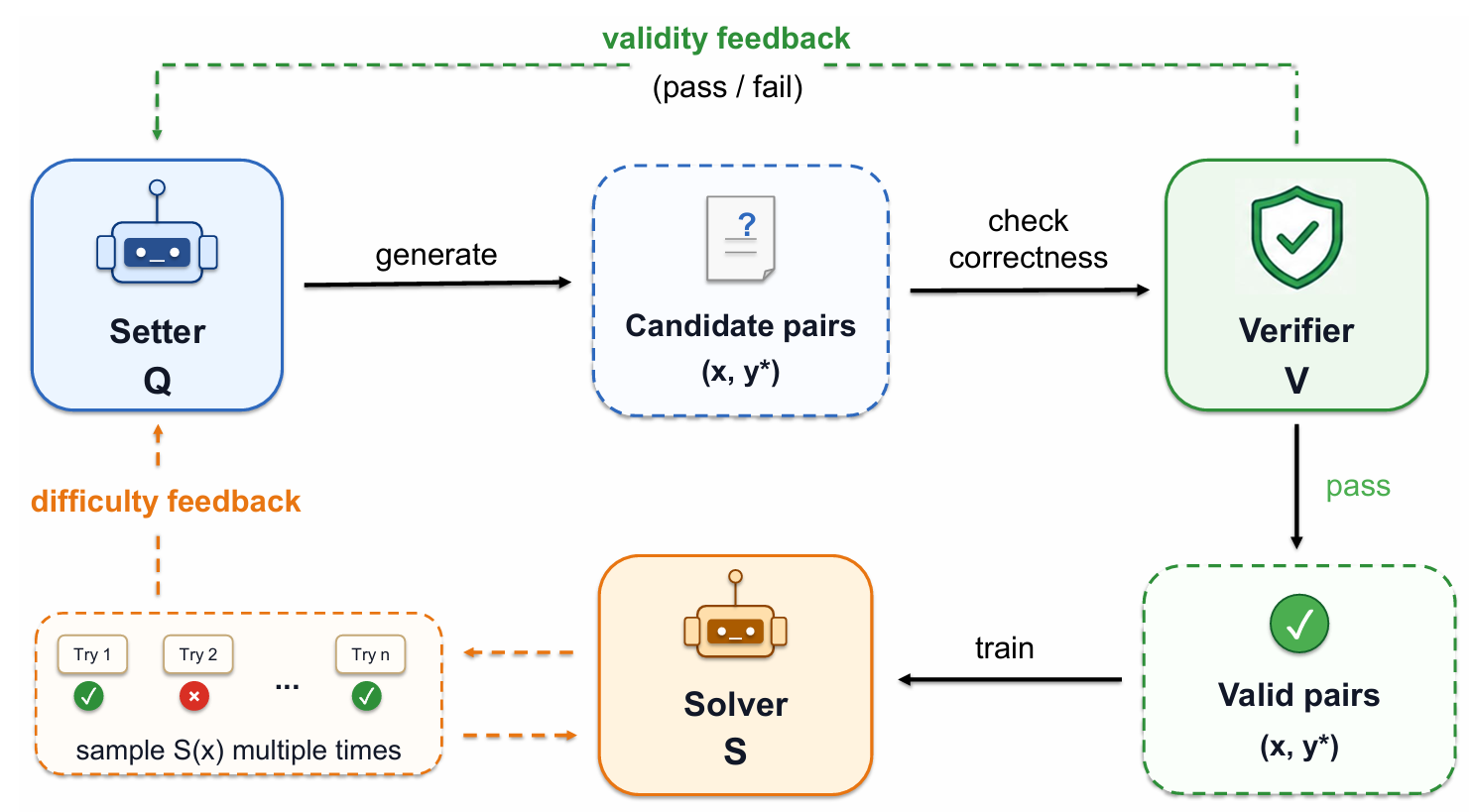
Verifier-Backed Hard Problem Generation for Mathematical Reasoning
07 May 2026
·
arXiv:2605.06660
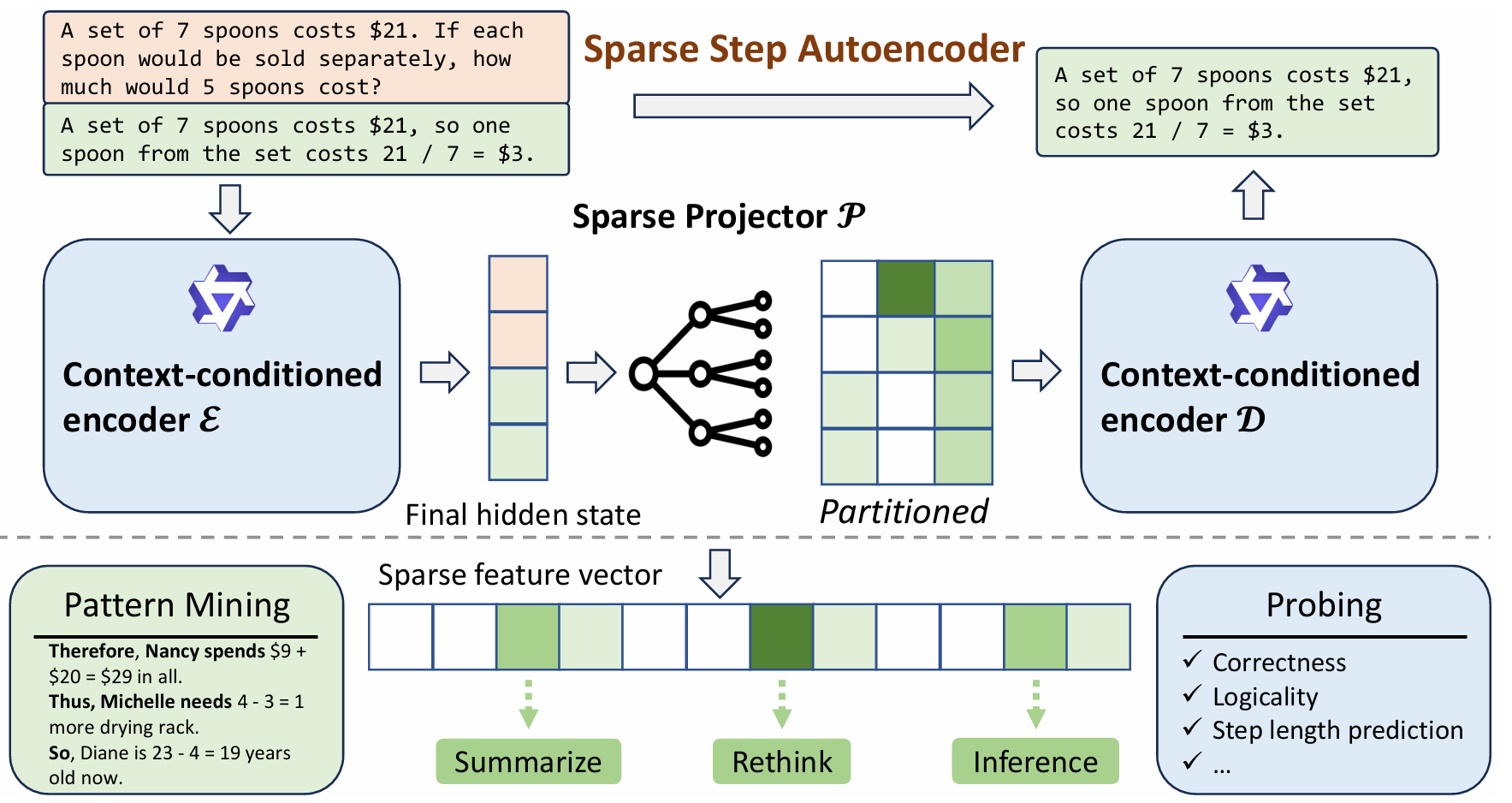
Step-Level Sparse Autoencoder for Reasoning Process Interpretation
ICML 2026
·
03 Mar 2026
·
arxiv:2603.03031
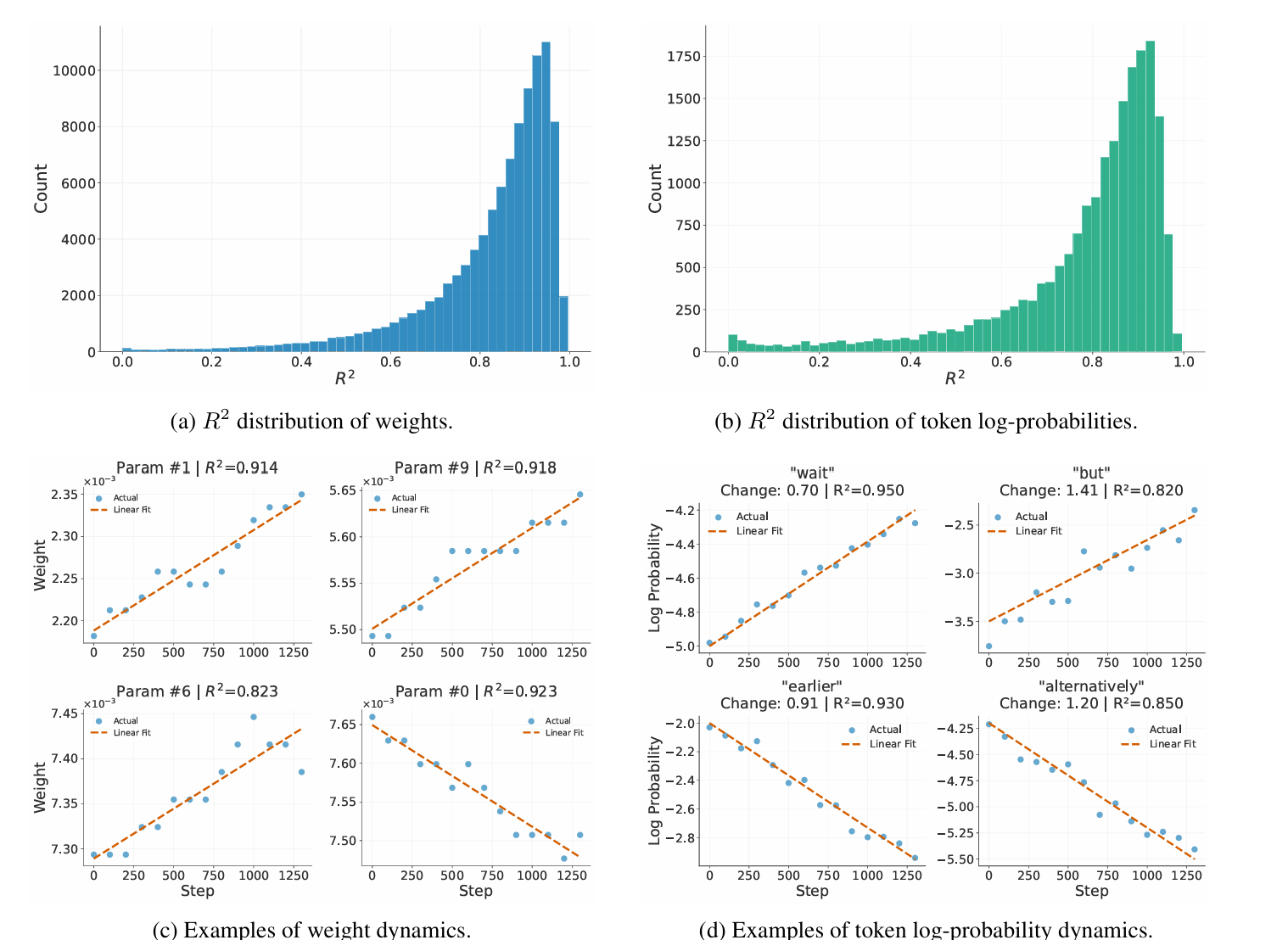
Linear Dynamics in the RLVR Training of Large Language Models
25 Jan 2026
·
arxiv:2601.04537
2025
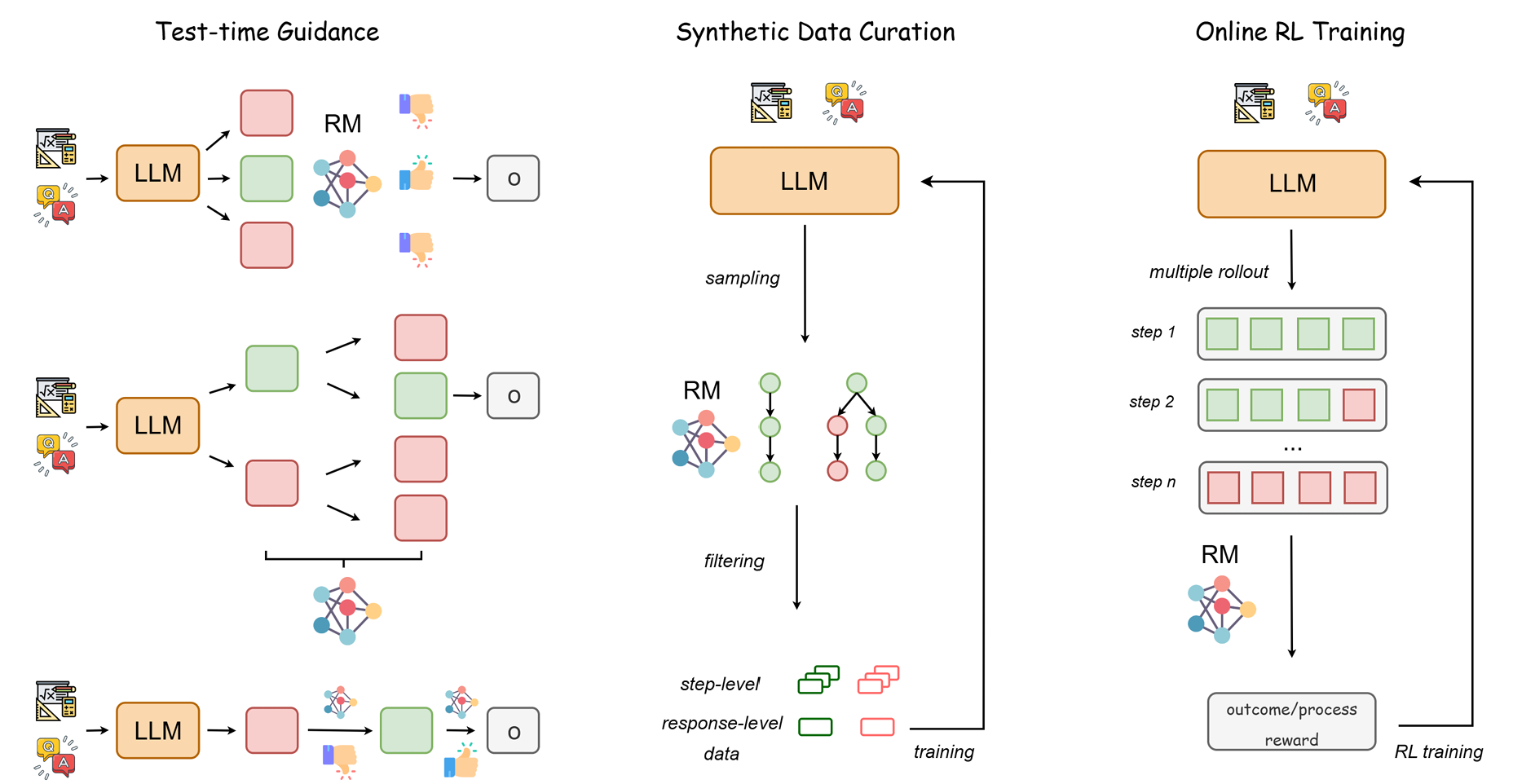
Enhancing Large Language Model Reasoning with Reward Models: An Analytical Survey
03 Oct 2025
·
arxiv:2510.01925
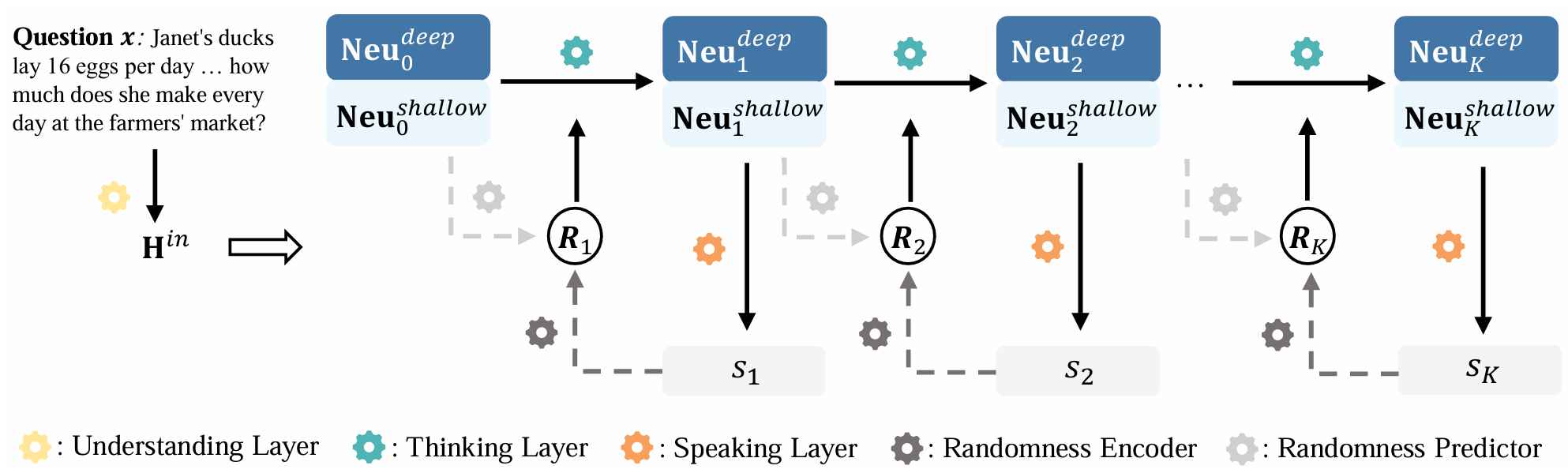
Deep Thinking by Markov Chain of Continuous Thoughts
29 Sep 2025
·
arXiv:2509.25020