Publications
2026
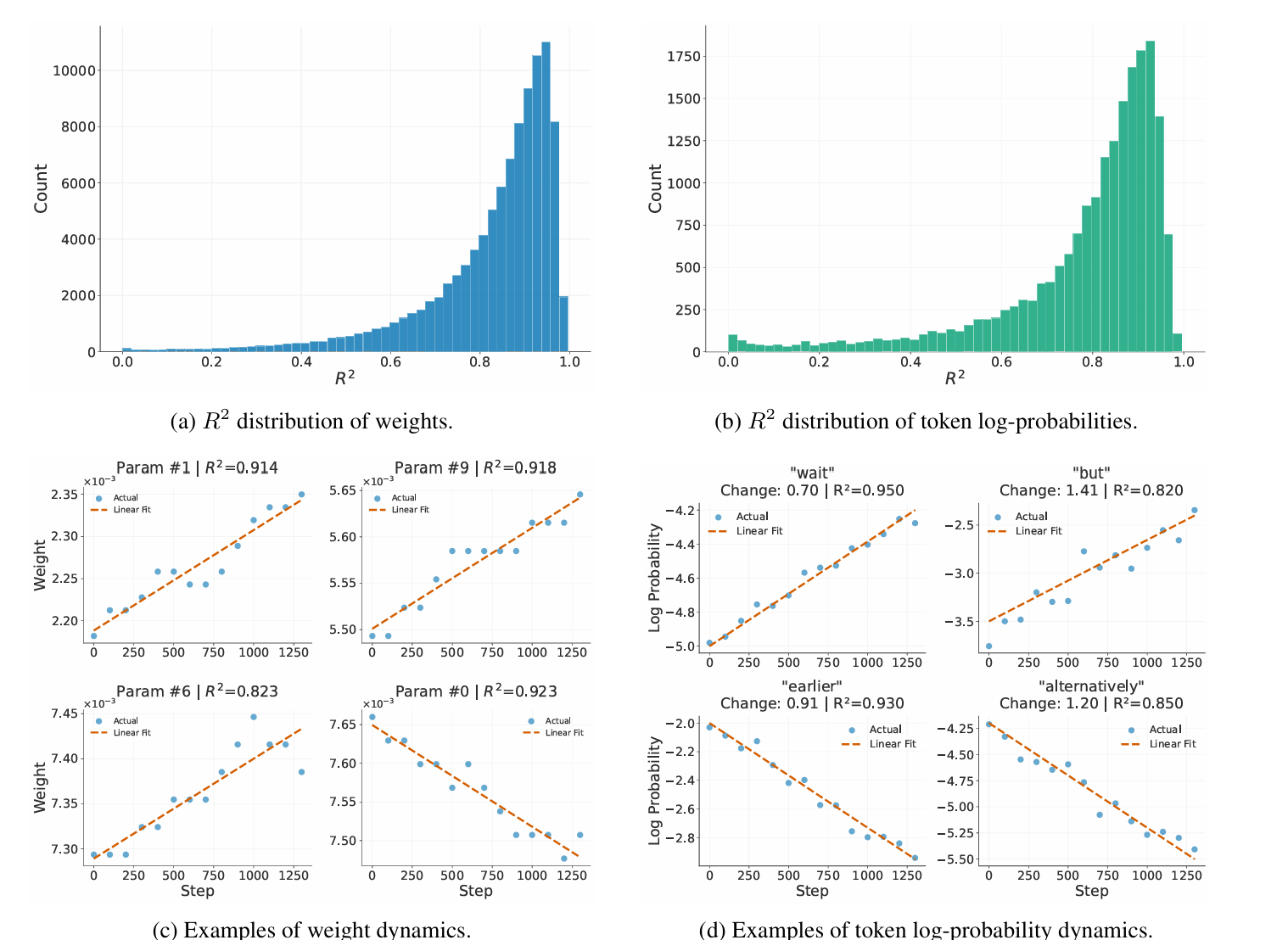
Not All Steps are Informative: On the Linearity of LLMs' RLVR Training
arXiv
·
25 Jan 2026
·
arxiv:2601.04537
2025
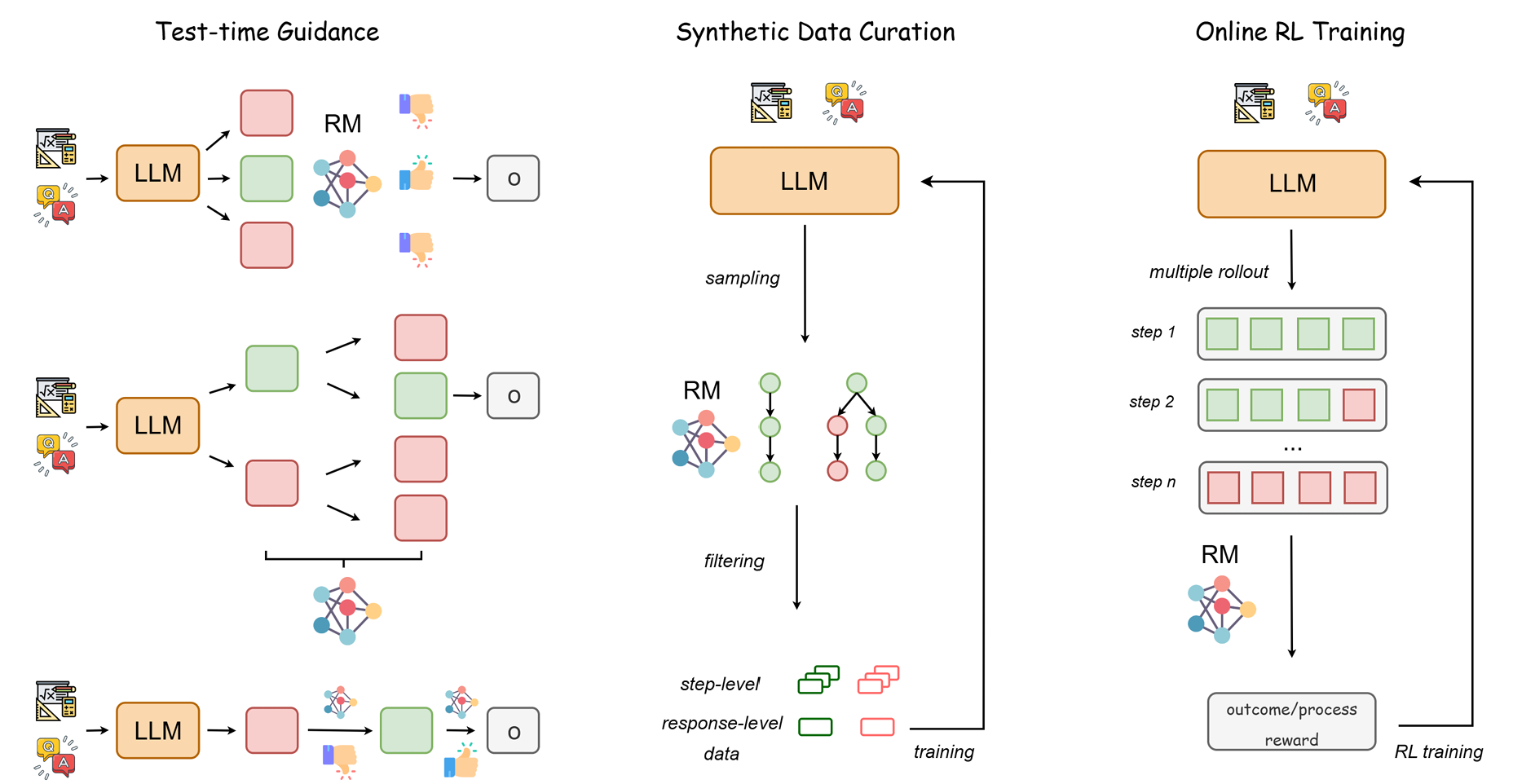
Enhancing Large Language Model Reasoning with Reward Models: An Analytical Survey
arXiv
·
03 Oct 2025
·
arxiv:2510.01925